Comenzar a trabajar en BI-Big Data en España
En los últimos años se produjo una explosión de nuevas tecnologías Open Source en la especialidad de la gestión de datos en todas sus etapas: obtención, almacenamiento, tratamiento y análisis. Esto ha generado nuevos roles de trabajo, en los que se necesitan trabajadores con competencias diversas, que en muchos casos son horizontales.
Existen dudas permanentes sobre los conocimientos que cada persona puede adquirir o reciclar si desea trabajar en el mundo de los Datos (llamaremos Datos a partir de ahora todo lo involucrado con ellos, para simplificar), ya sea porque es un estudiante recién recibido que desea comenzar una carrera orientada a esta especialidad, o si es una persona que tiene experiencia en Bases de Datos propietarias como Oracle, Teradata, o DB2.
Las mayores precisiones sobre este tema se encuentran en el mundo anglosajón, en donde se encuentran roles como Data Architect, Data Engineer, Data Analyst, Data Scientist, y más según pasa el tiempo. Muchos conocimientos son transversales entre especialidades, por lo que ya no sirve la vieja distinción entre negocio y sistemas de antaño.
¿Y en España? ¿Cómo puede comenzar una persona que desea hacer carrera desde cero (un estudiante, por ej.), o un trabajador que conoce tecnologías propietarias y desea reciclarse, o simplemente aprender?
Para brindar un panorama del mercado español, hemos consultado a Sonia Sanchez y Gerardo Vazquez, Gerente de Cuentas y Arquitecto de datos respectivamente, de BEEVA. Sonia aporta su visión personal de estos temas, indicando que “el área de Business Intelligence (BI) existe desde hace años, la que se nutría de bases de datos y herramientas de extracción y visualización propietarias”. No obstante, estas tecnologías eran muy caras, por lo que debían limitarse en cuanto a capacidad de almacenamiento y procesamiento. “Con la explosión de las tecnologías Open Source, si bien no se produce un nuevo paradigma tecnológico, se incrementa exponencialmente la capacidad de almacenamiento y procesamiento de datos; y se reducen notablemente los costes de utilización”. “Es entonces cuando las empresas pueden almacenar no ya sólo los datos estrictamente internos a la compañía, sino que también pueden incorporar datos externos, como por ej. hábitos de consumo de usuarios relevantes para el negocio (Twitter feeds, posts de Facebooks, contenido web, señales GPS, reportes detallados de llamadas de telecomunicaciones, emails, etc.), entre otras cosas, y del cruce de todos ellos obtener información con valor agregado para el negocio”, concluye Sonia.
Hasta aquí una síntesis del BI. ¿Y el Big Data? Gerardo Vazquez aporta su visión personal sobre este tema: “Big Data es un término que se utiliza para definir un conjunto de tecnologías de almacenamiento y procesamiento de datos. Algunas de estas son Hadoop, Mongo DB (la más fácil de aprender), AWS, Cloudera, Hortonworks, Hive, Spark, Presto, Cloudera Impala, Elastic Search, OpenShift, Neo4j, GAE (Google App Engine); y diversos lenguajes de programación y uso de librerías tales como Java, Python, Scala, JSON y R entre otros”. “Una persona que desee trabajar en Big Data debe tener una visión general de todas las tecnologías, un grado de expertise medio en algunas, y un expertise profundo en muchas” afirma. No obstante, “no es suficiente con conocer las tecnologías, sino que además debe ser capaz de optimizar el uso de las mismas”, aconseja Gerardo según su experiencia. “La ventaja de las tecnologías Open Source es que una persona puede montarse su entorno de aprendizaje y pruebas en su casa, lo que permite aprender de manera autodidacta. El aprender por cuenta propia es un requisito imprescindible para trabajar en Datos, las tecnologías que están hoy en dos años probablemente no existan, y haya que aprender nuevas”, concluye.
Por su parte, Sonia indica que para trabajar en el área de gestión y BI “la persona debe debe tener una visión general de todas las tecnologías, sin necesidad de profundizar en ninguna, ya que en caso de necesidad se recurre a los arquitectos”. Las tecnologías imprescindibles que indica son necesarias saber son “AWS, Cloud Computing, Azure, Cloudera, MapReduce y OpenStack”, por lo que se observa es un área donde reinan las tecnologías en la nube. Además, dicho profesional “debe ser capaz de empatizar con el cliente, ponerse en su lugar y entender sus necesidades”.Tanto Sonia como Gerardo entienden que el conocimiento de las filosofías Agile, y de integración y entrega continua de producto es imprescindible.
¿Cómo puede reciclarse hacia el mundo de los Datos Open Source un profesional con experiencia previa en tecnologías propietarias?
“Si la persona tiene experiencia en bases de datos propietarias, cuadros de mando, reportes, y tecnologías como Microstrategy, Business Object, Cognos, o Tableau; lo suyo probablemente es el mundo del BI”, indica Sonia.
“Si el profesional tiene experiencia en Sistemas Distribuídos y Administración, aconsejo aprender Hadoop como punto de partida. Si es Programador, puede comenzar con Spark y Flint; si es programador web puede aprender MongoDB”, aconseja Gerardo.
“Cualquier persona que se dedique a esto, tiene que tener en cuenta que las actitudes principales que debe tener son capacidad de autoaprendizaje, aceptación al cambio, y pasión por la tecnología permanentes”, concluyen ambos.
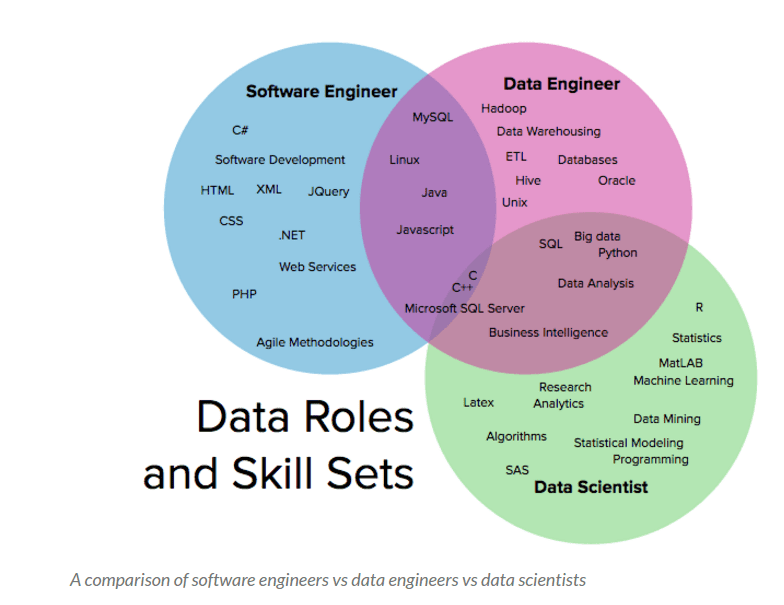
Roles en Big Data y BI y competencias adecuadas
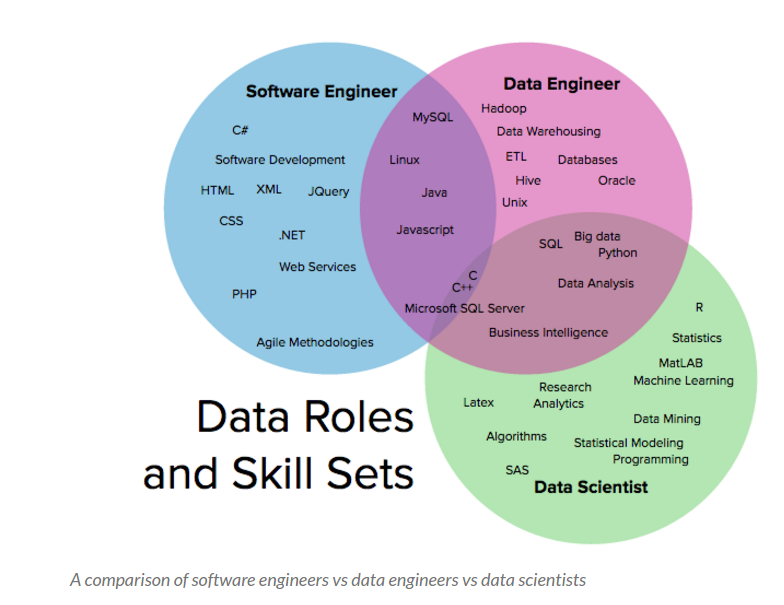
Fuente: Data scientists, data engineers, software engineers: the difference according to linkedin, por Ryan Swanstrom
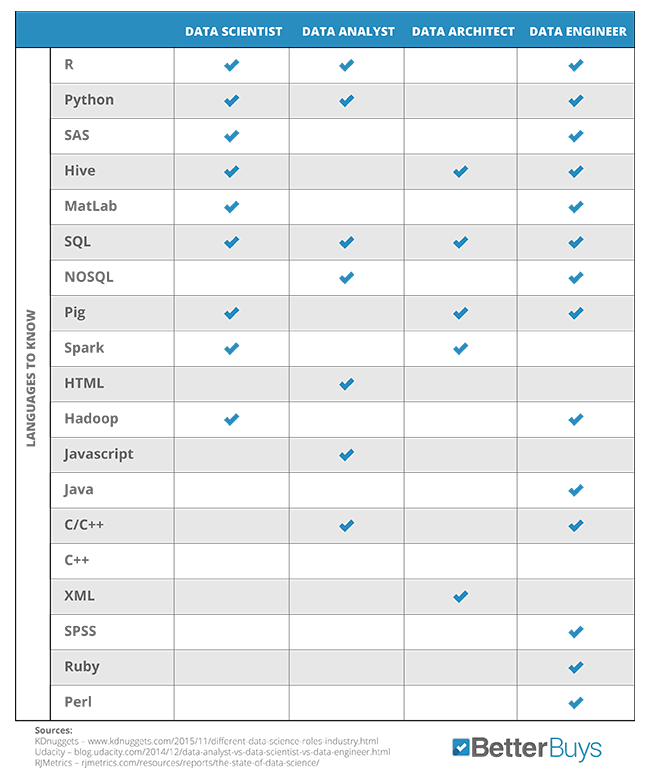
Conocimientos adecuados según rol en BI